一致性哈希
概述
目前的互联网服务提供商通常采用 服务器集群 来提高服务的质量. 使用集群后, 有一个问题, 就是如何快速定位数据存储在集群中的哪里.
普通集群
普通集群把固定的 key 映射到固定的结点上, 结点只存放各自 key 的数据. 如图:
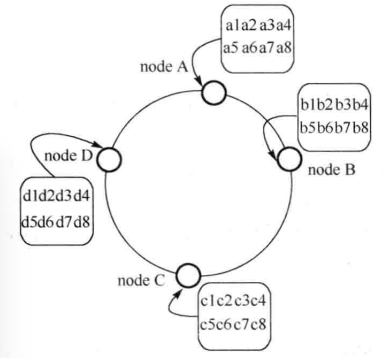
这种方法将 key 和结点的关系作为一张单独的表格进行维护, 当其中一个结点宕机后, 结点上的数据就需要迁移, 并更新表格.
局限性: 当需要查找某个 key 对应的数据时, 要遍历所有表格, 直到找到存放 key 对应的值的结点, 然后再去对应结点读取数据, 速度稍慢.
hash 集群
假设结点数为 n, 计算 key%n, 得到的结果为几, 将把 key 存储到对应的结点上. 这样可以不去维护一个上面所说的表格. 如图:
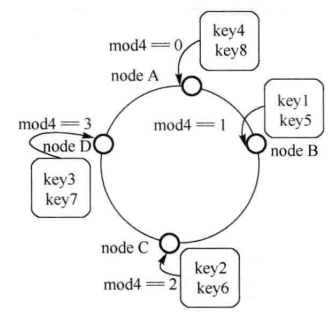
局限性: 如果有一个结点宕机了, 对数据进行迁移之后, 由于结点数变少, 取模后的结果也不一样了, 导致大部分的数据都要迁移, 而不仅仅是宕机的结点上的数据, 迁移之后, 还要重新映射一遍; 假设要加新结点进来, 也需要进行迁移工作.
一致性哈希
一致性哈希可以在添加或移除一个结点时, 尽可能小地改变已存在 key 的映射关系.
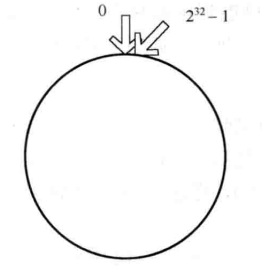
一致性哈希将整个哈希值空间组织成一个虚拟的圆环, 比如某哈希函数的值空间为 \(0 \sim 2^32-1\), 则整个哈希空间环如图:
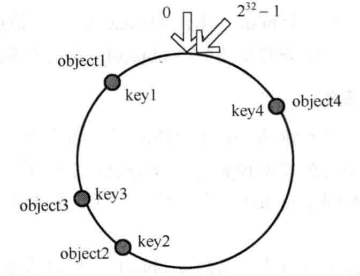
假设有四组数据 object1~object4, 通过哈希函数计算出的哈希值 key 在环上的分布如图:
将结点映射到哈希空间
将服务器映射到哈希空间: H(node A)=key A; H(node B)=key B; H(node C)=key C;
如图:
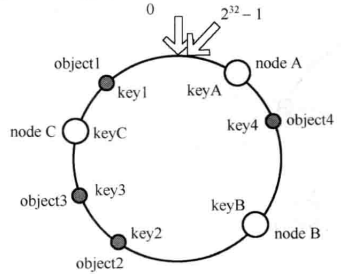
将数据映射到结点
在这个虚拟环内, 如果沿着顺时针方向从数据的 key 出发, 直到遇见第一个结点机器, 那么就将该数据存储在这个结点上. 因为数据和结点的哈希值是固定的, 因此这个结点必然是唯一和确定的. 这样数据和结点就一一对应了. 如图:
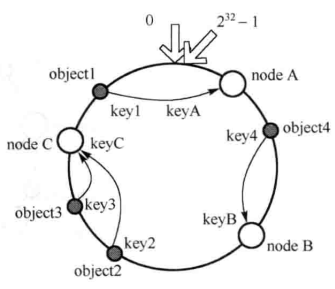
移除结点
假设 node B 出现问题, 则受到影响的数据就是原来映射在 node B 上的那些数据.
在这边, 需要做的改变就是, 将 object4 重新映射到 node C. 如图:
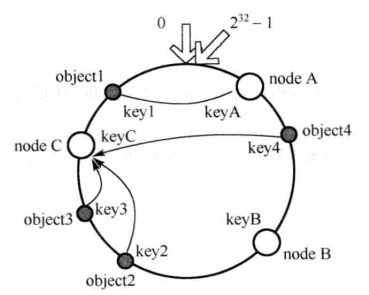
添加结点
如果添加一个 node D, 假设在 object2 和 object3 之间. 则受影响的只有 object2(沿 node D 的逆序遍历, 直到出现下一个 node 之间的数据). 如图:
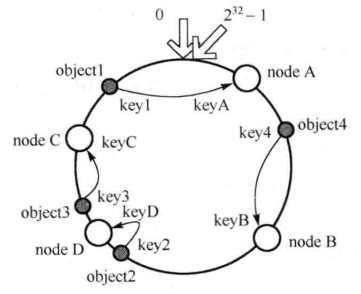
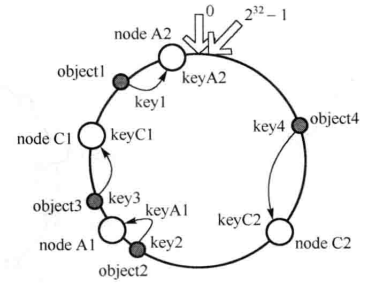
虚拟结点
有时候, 数据分布不平衡, 即某些结点存储了很多数据. 可以使用虚拟结点来解决这个问题.
虚拟结点: 实际结点在哈希空间的复制器, 一个实际结点对应了若干虚拟结点, 这个对应个数也称为复制个数, 虚拟结点在哈希空间中以哈希值排列.
在这个例子中, 如果设置复制个数为 2, 则会存在 4 个虚拟结点, node A1 和 node A2 代表 node A. 引入虚拟结点后, 分布可能如下:
Generated by Emacs 25.x(Org mode 8.x)
Copyright © 2014 - Pinvon - Powered by EGO
